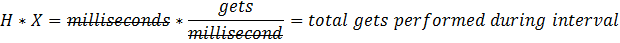This post is the second in a series on applying the Universal Scalability Law (USL) to Oracle OLTP. It follows up on my July post that gave an overview of the USL, and showed how Oracle "Average Active Sessions" (AAS) metric could be used to model concurrency "N".
The goal here is to estimate seriality and coherency parameters, Αlpha and Βeta respectively, that can be used to predict OLTP throughput as a function of concurrency "N". This is achieved by fitting the USL to observations of Oracle performance metrics that are easily queried from the Automatic Workload Repository (AWR). This model can be used for capacity planning and to set realistic monitoring targets. It also provides insight into the relative importance of serialization and coherency limits to system throughput.
The USL was developed by Dr. Neil Gunther, and is well described in his book Guerrilla Capacity Planning (Springer 2007, chapters 4-6). Craig Shallahamer places the USL into an Oracle context in his book Forecasting Oracle Performance (Apress 2007, chapter 10). The USL can be thought of as an extension of Amdahl's Law, which concerns speeding up a data processing task through parallelization. Amdahl's Law shows that the serialized parts of the data processing task will limit its speedup, so performance will eventually level off. The USL extends Amdahl's law by accounting for coherency in addition to concurrency. The USL's inclusion of coherency means that performance will actually decrease with excessive parallization, while it merely levels off under Amdahl's Law.
In the previous paragraph, I was intentionally vague with my use of the word paralllelization. Does this term mean adding more CPU processors, or does it mean adding more users? In other words, will the USL predict how many CPUs are needed to support a certain workload, or will it predict how many concurrent users can be supported by an existing software system? The answer: both! Dr. Gunther showed that the USL works for both hardware and software (Gunther 2007, chapter 6).
This post is divided into these sections:
- USL model detailed description
- Observations from a production database
- Estimate throughput at N = 1
- Normalize throughput observations to convert to capacityRatio
- Fit USL model to observations to estimate parameters Alpha and Beta
I implemented this model in Mathematica, and my notebook and data are available for download, along with a PDF version of the notebook. A later post will show how to implement this mode in the open source R programming language.
USL model detailed description
Define N as concurrency, the number of concurrent "users." Here it is modelled as Oracle "Average Active Sessions" (AAS), as explained in my July post.
Define X as throughput. Here it is modeled as Oracle "buffer gets" per millisecond as a function of N, and given the variable name throughPut (Gunther 2007 p. 52 eq. 4.20 as modified by p. 101 Section 6.3). Note that you are free to model your database using whichever throughput metrics are most appropriate. For example, many of Shallahamer's example use the Oracle metric "user calls." No single correct throughput metric exists, so you might want to experiment with several to see which has the best predictive ability.
throughPut = X(N)
Then X(1) is the throughput where N=1 (Ibid.). It is obviously not possible to set N=1 in a production Oracle database when using this N=AAS model, since AAS is estimated through observation rather than set to arbitrary values. The variable name throughPutOne is used here for X(1) and its value is estimated by linear regression as shown below.
throughPutOne = X(1)
Define C(N) as the "capacity ratio" or "relative capacity" as the ratio of X(N) to X(1) at a given value of N (Gunther 2007 p. 77). The variable capacityRatio is used here for C(N).
capacityRatio = C(N) = X(N)/X(1)
Gunther's Universal Scalability Law (USL) as modified for software scalability is shown below. (Gunther 2007 p. 101 eq. 6.7). The variable n is used here for N. A goal of this study is to estimate parameters Alpha and Beta, which characterize seriality and coherency respectively.
capacityRatio = n / (1 + Alpha (n - 1) + Beta n (n - 1))
Define N as concurrency, the number of concurrent "users." Here it is modelled as Oracle "Average Active Sessions" (AAS), as explained in my July post.
Define X as throughput. Here it is modeled as Oracle "buffer gets" per millisecond as a function of N, and given the variable name throughPut (Gunther 2007 p. 52 eq. 4.20 as modified by p. 101 Section 6.3). Note that you are free to model your database using whichever throughput metrics are most appropriate. For example, many of Shallahamer's example use the Oracle metric "user calls." No single correct throughput metric exists, so you might want to experiment with several to see which has the best predictive ability.
throughPut = X(N)
Then X(1) is the throughput where N=1 (Ibid.). It is obviously not possible to set N=1 in a production Oracle database when using this N=AAS model, since AAS is estimated through observation rather than set to arbitrary values. The variable name throughPutOne is used here for X(1) and its value is estimated by linear regression as shown below.
throughPutOne = X(1)
Define C(N) as the "capacity ratio" or "relative capacity" as the ratio of X(N) to X(1) at a given value of N (Gunther 2007 p. 77). The variable capacityRatio is used here for C(N).
capacityRatio = C(N) = X(N)/X(1)
Gunther's Universal Scalability Law (USL) as modified for software scalability is shown below. (Gunther 2007 p. 101 eq. 6.7). The variable n is used here for N. A goal of this study is to estimate parameters Alpha and Beta, which characterize seriality and coherency respectively.
capacityRatio = n / (1 + Alpha (n - 1) + Beta n (n - 1))
Here is how Mathematica displays and simplifies this formula:


Observations from a production database
I obtained Oracle performance metric data observations from an AWR query on a production system. This query is heavily documented, so see the SQL text for details. It uses both "subquery factoring" (aka "common table expressions" and lead() analytic function.
This query calculates deltas of hourly snapshots of several Oracle resource usage counters (see this article for more about AWR). For this USL model, we need only these two columns:
- DB_TIME_CSPH = centiseconds of "DB Time" used in one hour. As explained here, "DB time" is the sum of time spent on the CPU and in "active" waits
- BUFFER_GETS_PH = buffer gets done in one hour, a measure of throughput.
See the notebook or PDF for details about importing these query results into Mathematica. One of the trickiest parts is converting to the correct units of measure, which always seems trickier than it should!
Estimate throughput at N = 1
As mentioned above, it is obviously not possible to set N=1 in a production Oracle database when using this N=AAS model, since AAS is estimated through observation rather than set to arbitrary values. We will use linear regression on this subset to estimate the throughput at AAS=1.
I used the subset of observations where AAS was less than 1.5. This estimated throughput at AAS=1 is needed to normalize throughput observations to unitless capacityRatio.
See the notebook or PDF for details about doing the linear regression with Mathematica. I show below the regression line along with the subset of observations. I estimate throughPutOne = X(1) = 101.62 buffer gets per millisecond at AAS=1.

Normalize throughput observations to convert to capacityRatio
I show below how to normalize throughput observations to convert to capacityRatio = C(N) = X(N)/X(1).
I include a sanity check and plot.

Fit USL model to observations to estimate parameters Alpha and Beta
I use Mathematica's FindFit[data,expr,pars,vars] to estimate parameters Alpha and Beta, which characterize seriality and coherency respectively. The capacity ratio form of the USL is repeated below. (Gunther 2007 p. 101 eq. 6.7). The variable n is used here for N and is the first column in the nCapacityRatio (nested list) table and can be thought if as the independent variable. The second column of data, the normalized capacity ratio from immediately above, is considered to be the observed value of the capacityRatio formula.
capacityRatio = n / (1 + Alpha (n - 1) + Beta n (n - 1))

I prepare the USL model by substituting best fit parameters and simplifying.

Finally, I plot USL model along with the normalized observations. This model well predicted system throughput, and helped to fine tune production monitoring and troubleshooting protocols.

Downloads
- Mathematica notebook and data
- A PDF version of the notebook